

데이터 분석을 위한 데이터 스크래핑
✔️ 공공데이터 API 신청
✔️ 공공데이터 API 활용 데이터 스크래핑
✔️ 공공데이터 API 신청
공공데이터 API 신청
공공데이터 포털
정부가 운영하는 공공데이터 통합 제공 플랫폼
공공기관이 보유한 데이터를 관리하고 개방하여 검색, 다운로드하여 데이터를 활용
공공데이터 API 신청 과정
1. 공공데이터포털 로그인 및 원하는 데이터 검색
2. API 활용 신청
3. API 키 발급 및 일반 인증키로 인증하여 API 활용 데이터 스크랩핑 수행 가능
1. 공공데이터포털 로그인 및 원하는 데이터 검색
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
로그인 이후 원하는 데이터 검색
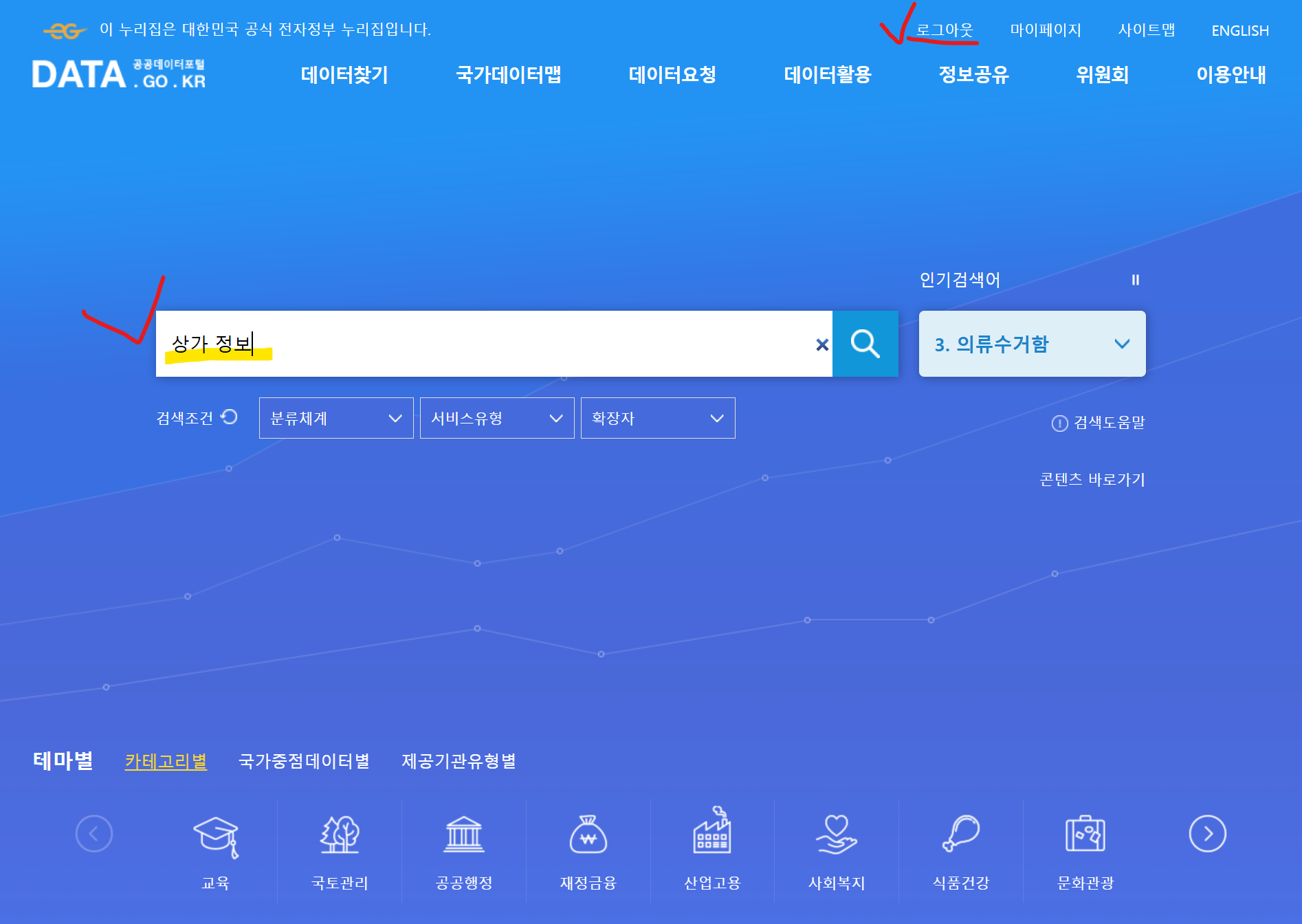
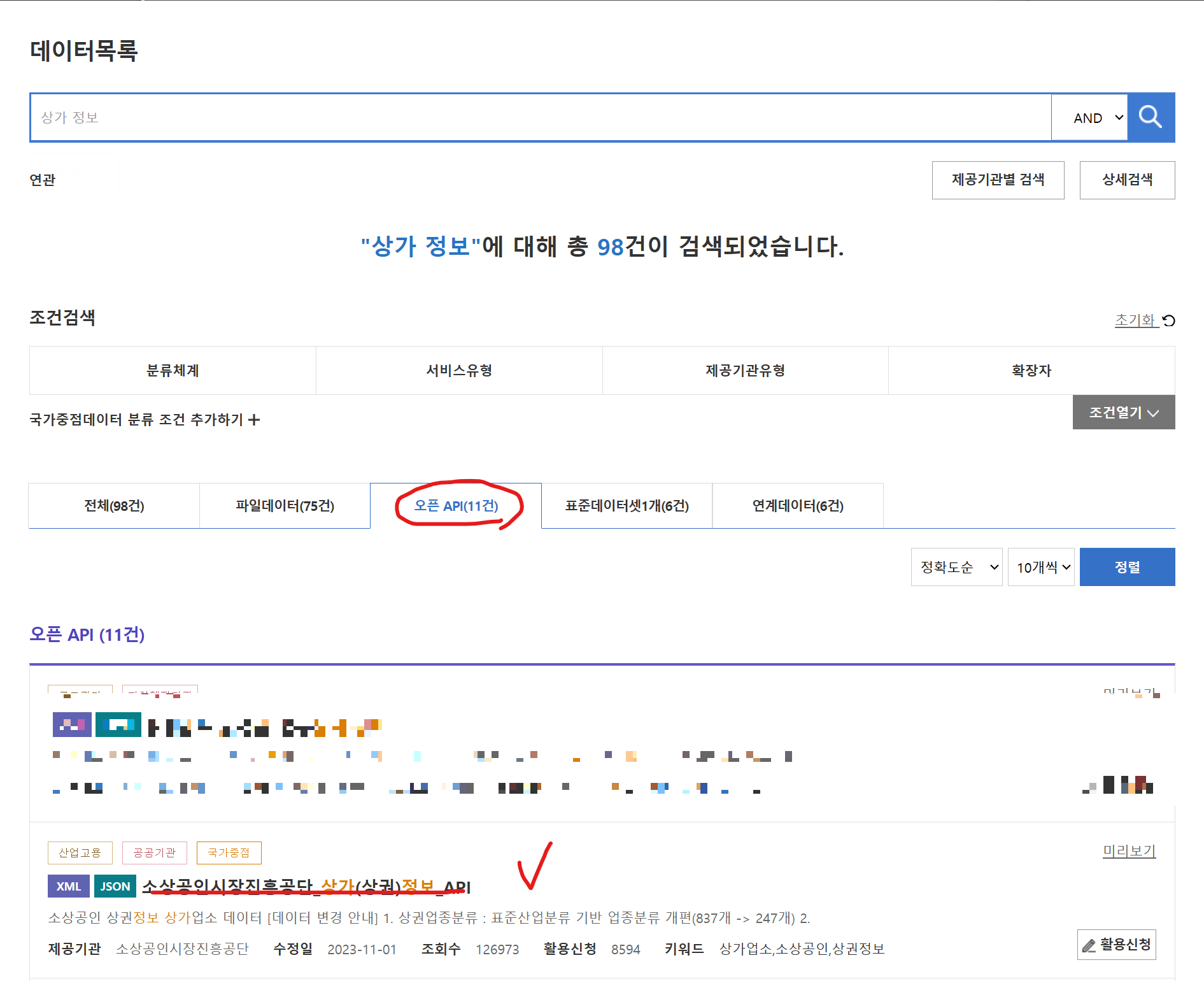
2. API 활용 신청
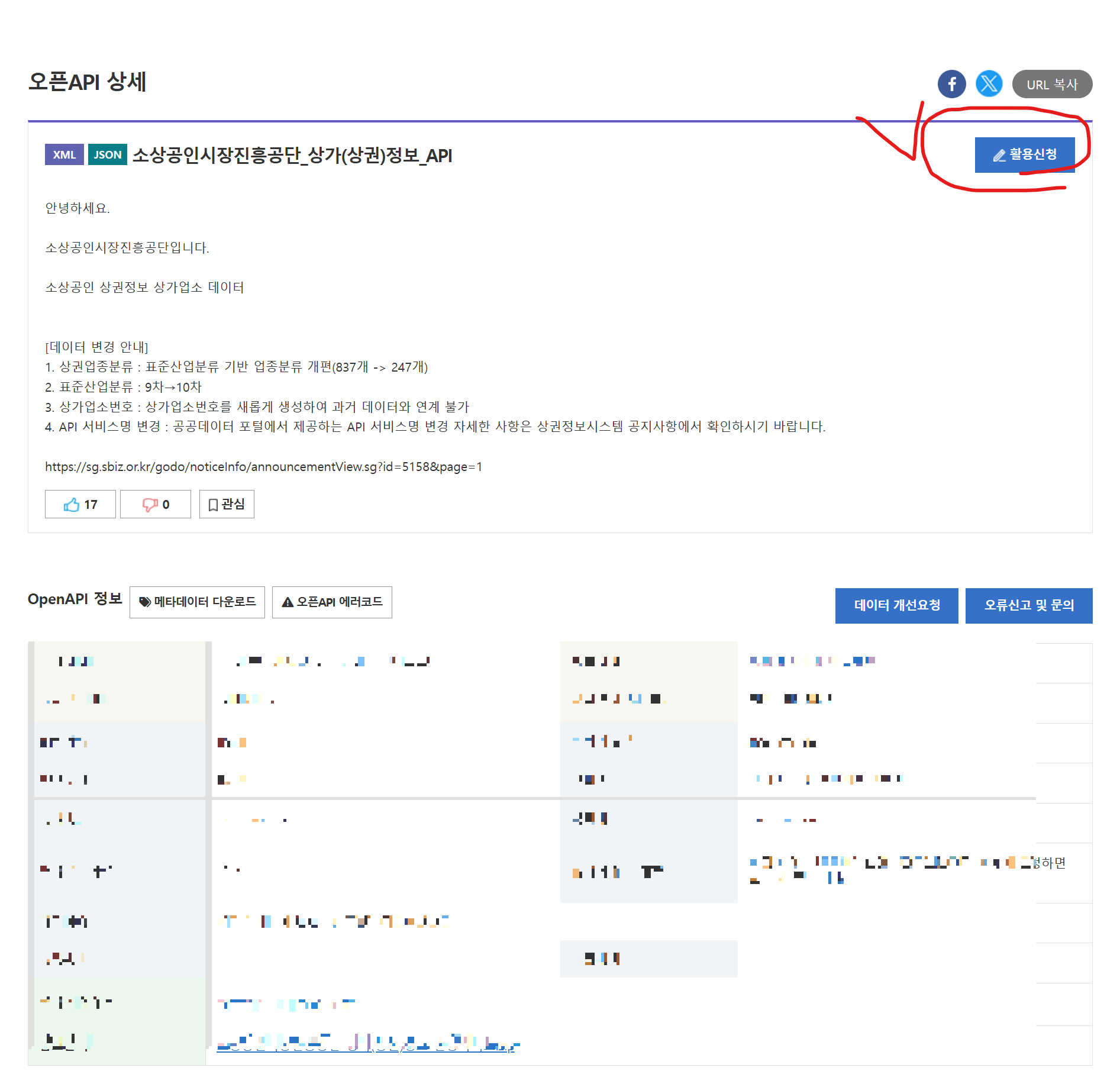
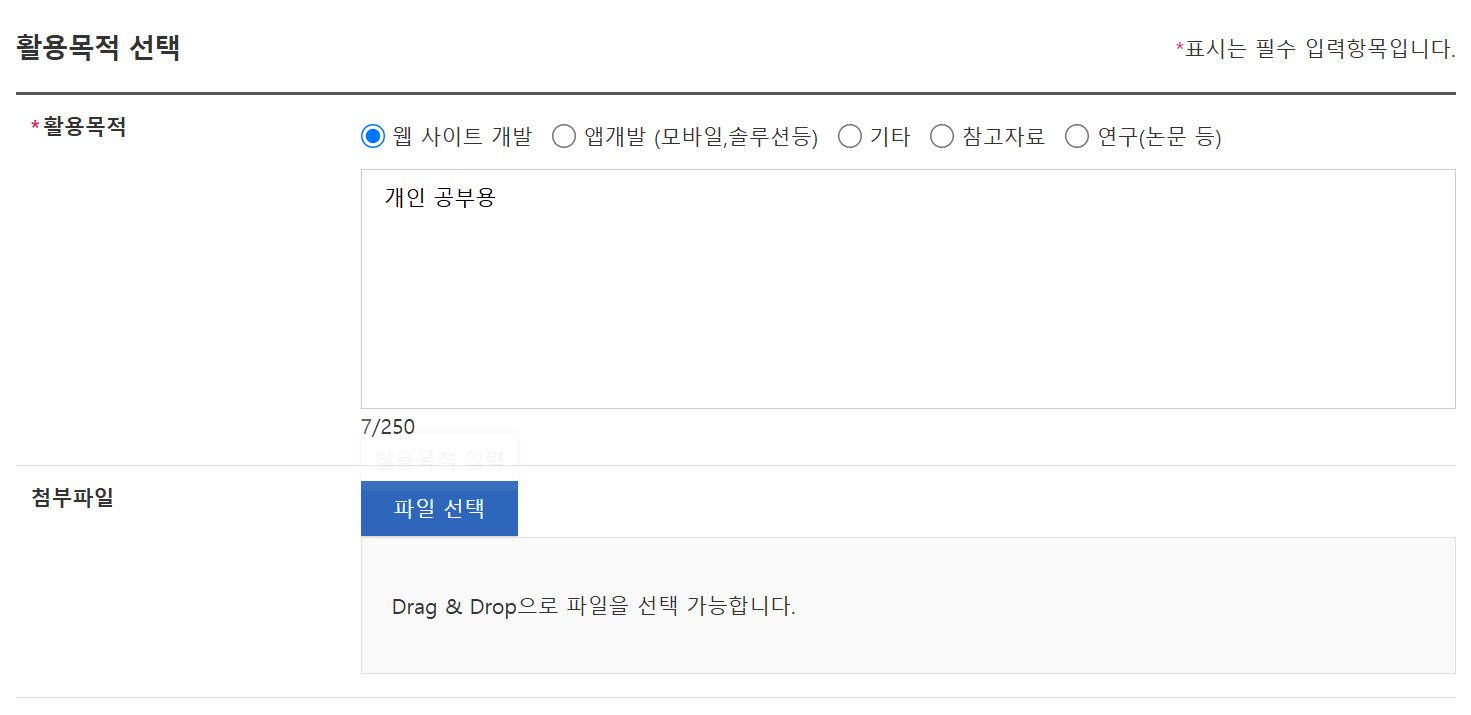
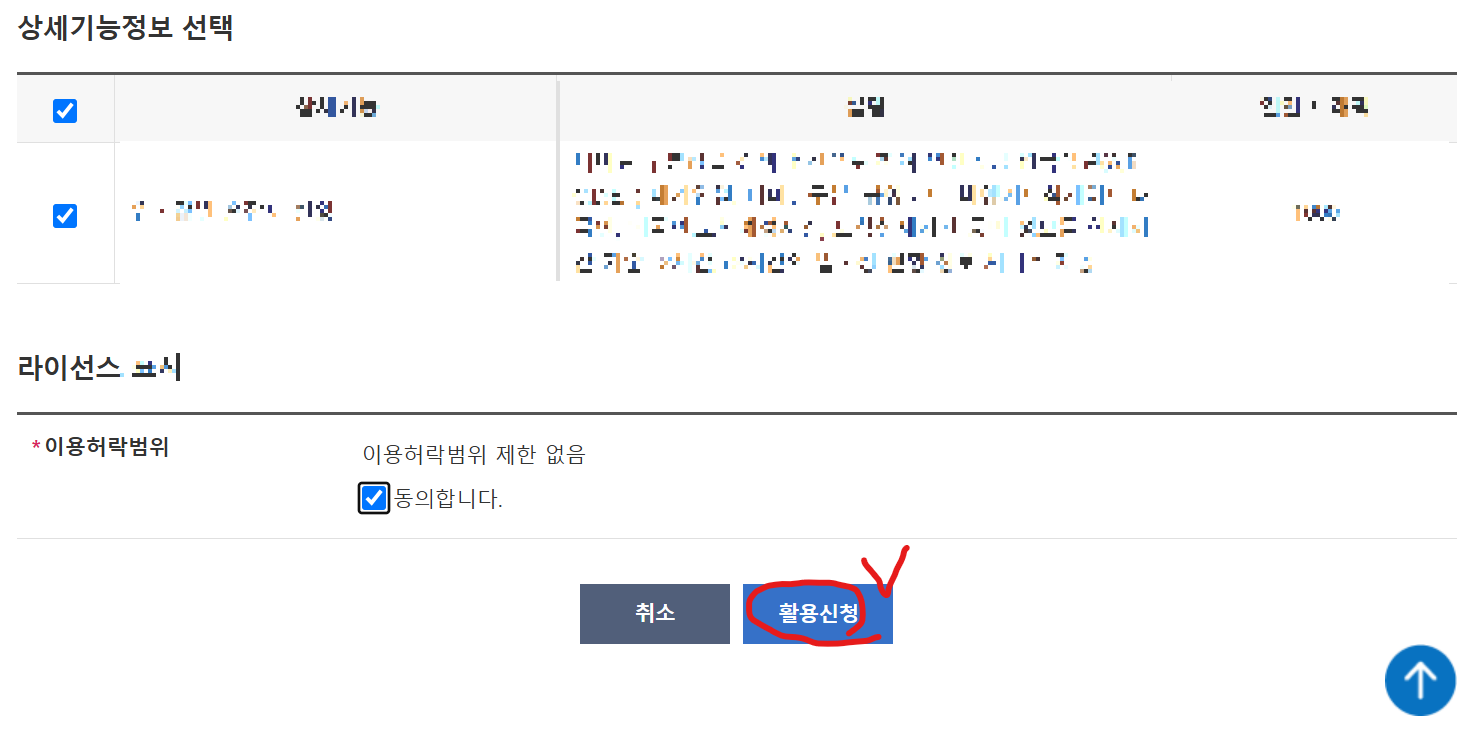
3. API 키 발급
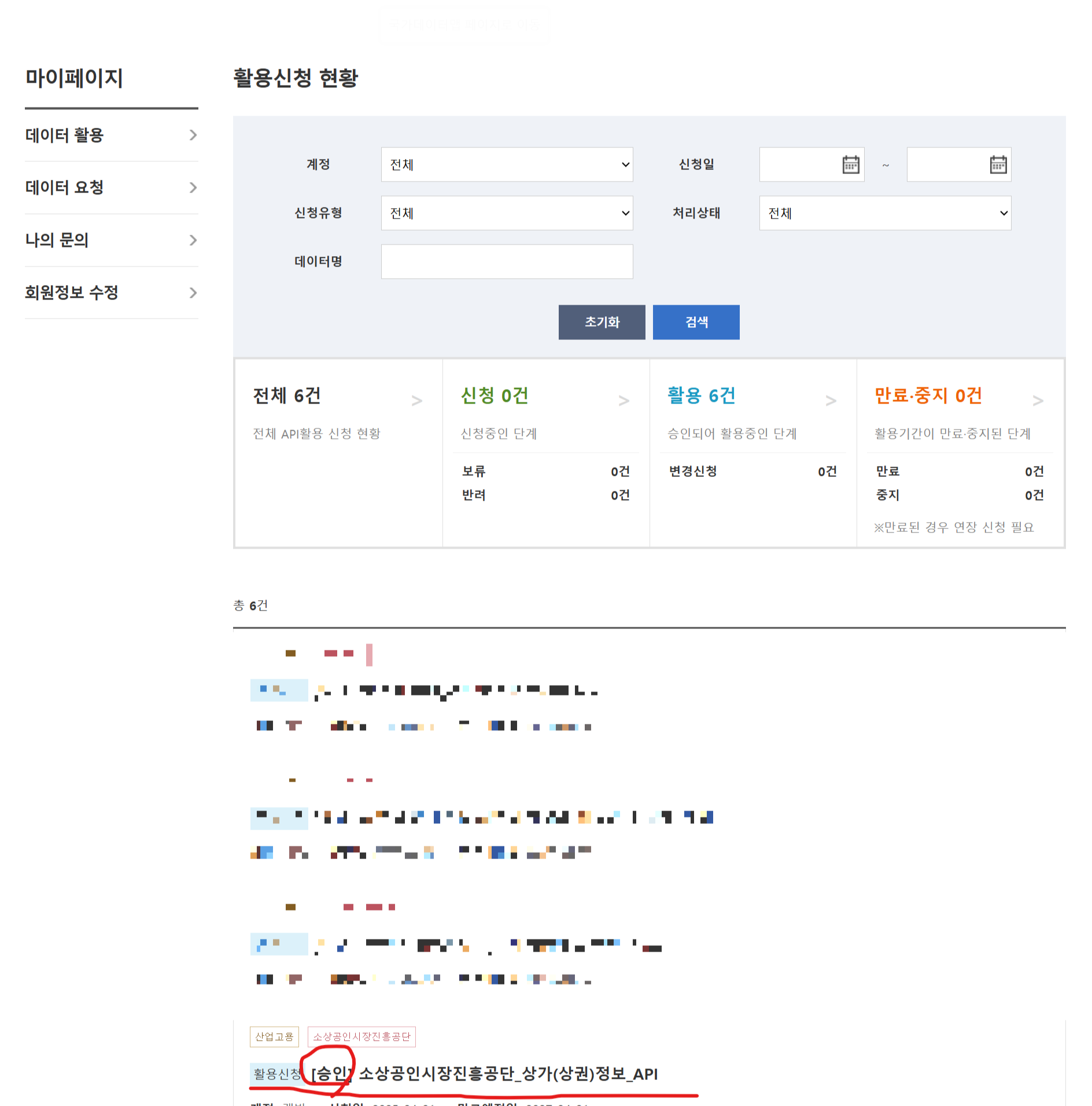
일반 인증키로 인증하여 API 활용 데이터 스크랩핑 수행 가능
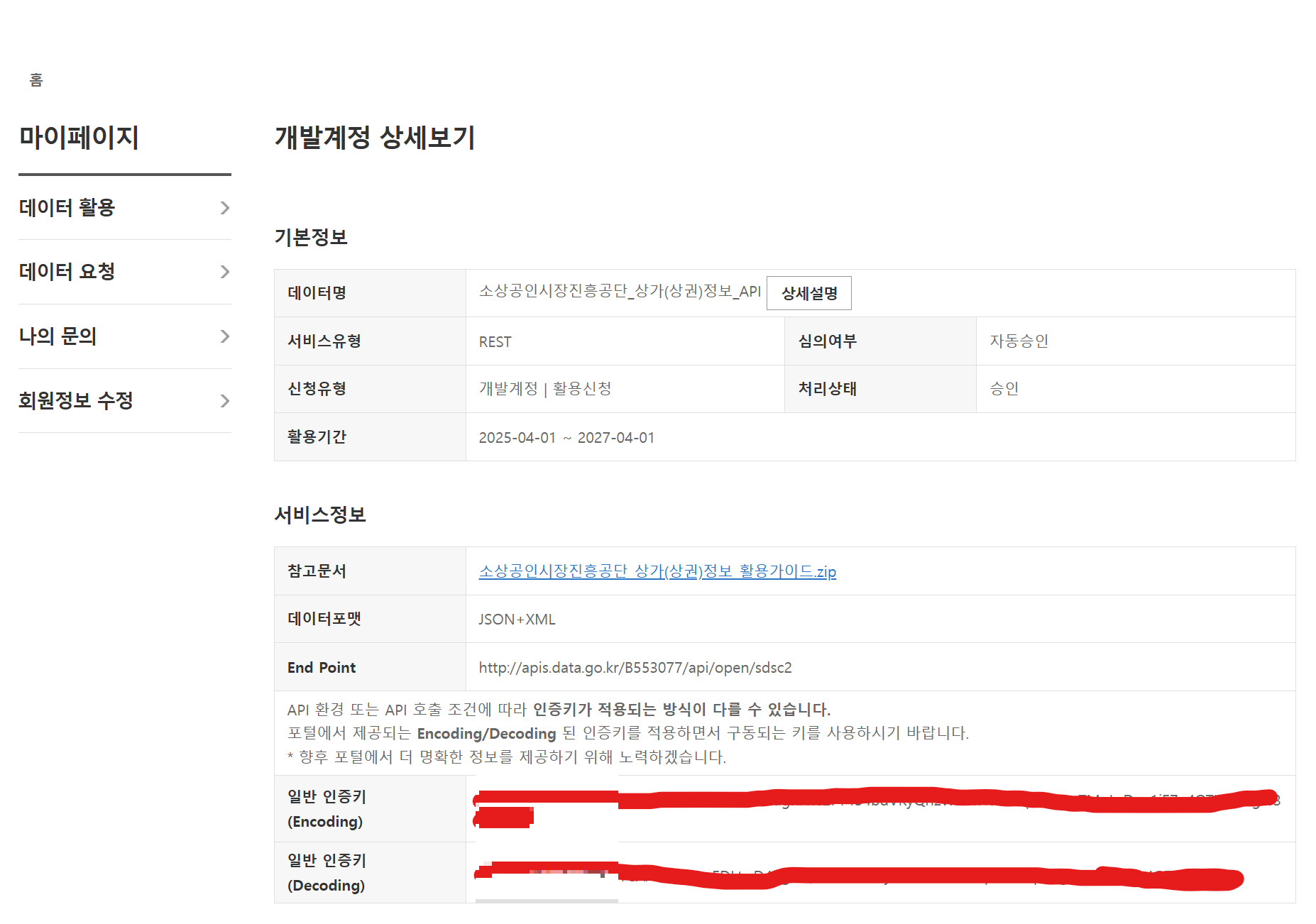
✔️ 공공데이터 API 활용 데이터 스크래핑
데이터 스크래핑_공공데이터 API(상권 정보 데이터)
공공데이터 API 활용 상권(상가) 정보 데이터 스크래핑_소분류 기준
(학습 목적으로 수행하였습니다)
1. 라이브러리 임포트 및 발급받은 서비스키를 할당
2. 원하는 데이터 수만큼 1페이지를 불러와서 데이터 확인
3. 전체 데이터 수와 페이지 수를 확인
4. 딕셔너리 형태의 데이터를 데이터프레임으로 변환 함수 설정
5. 전체 페이지를 활용하여 전체 데이터 수집 및 데이터프레임 확인
소상공인시장진흥공단_상가(상권)정보_API
안녕하세요. 소상공인시장진흥공단입니다. 소상공인 상권정보 상가업소 데이터 [데이터 변경 안내] 1. 상권업종분류 : 표준산업분류 기반 업종분류 개편(837개 -> 247개) 2. 표준산업분류 : 9차→10
www.data.go.kr
라이브러리 임포트 및 발급받은 서비스키를 할당
import requests import pandas as pd Service_key = 'Paste Your Service Key'
원하는 데이터 수만큼 1페이지를 불러와서 데이터 확인 및 전체 데이터 수와 페이지 수를 확인
# 상권 데이터를 수집 url 할당 # 파라미터 설정(상가 상권데이터의 참고문서의 파라미터 구성 확인) url = 'http://apis.data.go.kr/B553077/api/open/sdsc2/storeListInUpjong' payload = dict(divId='indsLclsCd', key='I2', numOfRows=1000, pageNo=1, type='json',servicekey=Service_key) # requests 모듈 get 방식으로 받아서 받아온 데이터 r에 할당 r = requests.get(url, params=payload) # r에 할당된 전체 url과 상태 코드 확인 # json 형식의 데이터를 딕셔너리로 변환하여 할당 print(r.url) print(r.status_code) data = r.json() # 전체 데이터의 수 확인 및 n_data에 할당 n_data = data['body']['totalCount'] # print(n_data) # 전체 페이지 수 계산 및 total_pages에 할당 total_pages = (int(data['body']['totalCount'])//1000)+1 print(total_pages)
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
딕셔너리 형태의 데이터를 데이터프레임으로 변환
# 받아온 데이터를 딕셔너리 형태로 저장하여 데이터프레임으로 변환 def unpack_data(response): # 받아온 데이터 딕셔너리 형태로 저장하여 result에 할당 result = {} # 데이터 변환 for item in response['body']['items']: for key, value in zip(response['header']['columns'], item.values()): result.setdefault(key, []).append(value) df = pd.DataFrame(result) return df
결과를 확인하고 싶다면 def와 return을 제거하여 확인할 수 있습니다. 결과는 코드에 따라 달라질 수 있습니다.
전체 페이지를 활용하여 전체 데이터 수집 및 데이터프레임 확인
# 페이지 번호 초기화 page = 1 # 각 페이지 데이터프레임을 result_dfs에 할당 result_dfs = [] # 전체 페이지 데이터 수집 반복문 while True: # 상권 데이터를 수집 url 할당 # 파라미터 설정(상가 상권데이터의 참고문서의 파라미터 구성 확인) url = "http://apis.data.go.kr/B553077/api/open/sdsc2/storeListInUpjong" payload = dict(servicekey=service_key, divId="indsSclsCd", key="I21006", numOfRows=1000, pageNo=page, type="json") # r에 할당된 전체 url과 상태 코드 확인 r = requests.get(url, params=payload) # r에 할당된 전체 url과 상태 코드 확인 # json 형식의 데이터를 딕셔너리로 변환하여 response에 할당 print(r.url, end="\r") print(r.status_code, end="\r") response = r.json() # 전체 데이터의 수와 전체 페이지의 수 확인 및 할당 total_page = (response['body']['totalCount'] // 1000) + 1 # 데이터프레임으로 변환된 데이터를 리스트 형식으로 result_dfs에 할당 result_dfs.append(unpack_data(response)) print(f"{page}/{total_page} 수집중", end="\r") # page가 전체 페이지보다 작은 경우 +1씩 더함 # 위 경우가 아닌 경우는 멈춤 if page < total_page: page += 1 else: break time.sleep(0.2) # 저장된 각 페이지의 데이터프레임을 결합하여 하나의 데이터프레임으로 형성 result = pd.concat(result_dfs, index_ignore=True) result

이번 내용에서는 공공데이터 API 신청 및 공공데이터 API 활용 데이터 스크래핑에 대해 알아보았습니다.
파이썬(Python)을 활용한 데이터 스크래핑을 공부하고 정리해 나갈 예정이니,
파이썬으로 데이터 스크래핑을 공부하는데 도움이 되었으면 좋겠습니다.
데이터 분석과 관련된 다양한 정보들이 확인하고 싶다면
관심 있는 분들은 방문해서 좋은 정보 얻어가시길 바랍니다.
ECODATALIST
데이터 분석 공부 열심히 하는 중😁
everyonelove.tistory.com
'Python > 데이터 분석을 위한 데이터 스크래핑' 카테고리의 다른 글
| [Python] 데이터 스크래핑_ XML 데이터 스크래핑 및 공공데이터 API 활용 XML 데이터 스크래핑 (0) | 2025.04.07 |
|---|---|
| [Python] 데이터 스크래핑_requests 모듈을 사용한 네이버 API 활용 데이터 스크래핑 (0) | 2025.04.03 |
| [Python] 데이터 스크래핑_네이버 API 신청 및 네이버 API 활용 데이터 스크래핑 (1) | 2025.04.02 |