

데이터 분석을 위한 데이터 스크래핑
✔️ requests 모듈
✔️ requests 모듈_네이버 API 활용
✔️ requests 모듈
requests 모듈
requests 모듈
HTTP프로토콜을 사용할 수 있게 해주는 모듈
requests 모듈 설치
conda install requests
pip install requests
requests 모듈 사용법
1. 모듈 불러오기 : import requests
2. url 부분만 변수에 저장
3. url 파라미터 : payload = {파라미터1: value, 파라미터2: value, ...}
API를 활용하기 위한 설명서에서 파라미터 부분 확인하고 적용
4. header
headers = {key: value}
5. HTTP 요청 보내기 : get 방식, post 방식
get : r = requests.get(url, params=payload, headers=headers)
post : r = requests.post(url, data={key:value})
6. 만들어진 url 확인 : print(r.url)
7. 응답 코드 확인 : print(r.status_code)
8. 응답 요소 출력 : r.text, r.content, r.json()
NAVER Developers
네이버 오픈 API들을 활용해 개발자들이 다양한 애플리케이션을 개발할 수 있도록 API 가이드와 SDK를 제공합니다. 제공중인 오픈 API에는 네이버 로그인, 검색, 단축URL, 캡차를 비롯 기계번역, 음
developers.naver.com
검색 > 블로그 - Search API
검색 > 블로그 블로그 검색 개요 개요 검색 API와 블로그 검색 개요 검색 API는 네이버 검색 결과를 뉴스, 백과사전, 블로그, 쇼핑, 웹 문서, 전문정보, 지식iN, 책, 카페글 등 분야별로 볼 수 있는 API
developers.naver.com
데이터 스크래핑_requests 모듈 활용
import requests # 발급받은 클라이언트 아이디와 시크릿을 복사붙여 넣어 할당 Client_Id = 'Paste Your Client ID' Client_Secret = 'Paste Your Cliuent Secret' # 동일하게 블로그 검색 데이터 찾기 위한 url 설정 url = "https://openapi.naver.com/v1/search/blog" # 네이버 개발자 페이지의 블로그 검색에서 파라미터 확인하여 적용 payload = {'query': '파이썬', 'display': 100,'start': '1', 'sort': 'sim'} # 자신의 Client_Id, Client_Secret를 확인하고 할당하여 적용 headers = {'X-Naver-Client-Id': Client_Id, 'X-Naver-Client-Secret': Client_Secret} # requests 모듈 get 방식으로 받아서 받아온 데이터 r에 할당 r = requests.get(url, params=payload, headers=headers)
# prarms에 할당된 payload 확인 print(payload) # headers에 할당된 headers 확인 print(headers)
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
# r에 할당된 url 확인 print(r.url) # r에 할당된 응답 코드 확인 # 200 : 정상 / 400 : 코드(작성자)의 오류 가능성 높음 / 500 : 서버 문제 가능성 높음 print(r.status_code) # r에 할당된 파일의 문자열을 json에서 딕셔너리로 변환 data = r.json() data
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
import pandas as pd # data에 할당된 데이터를 데이터프레임 형식으로 확인 df = pd.DataFrame(data) df
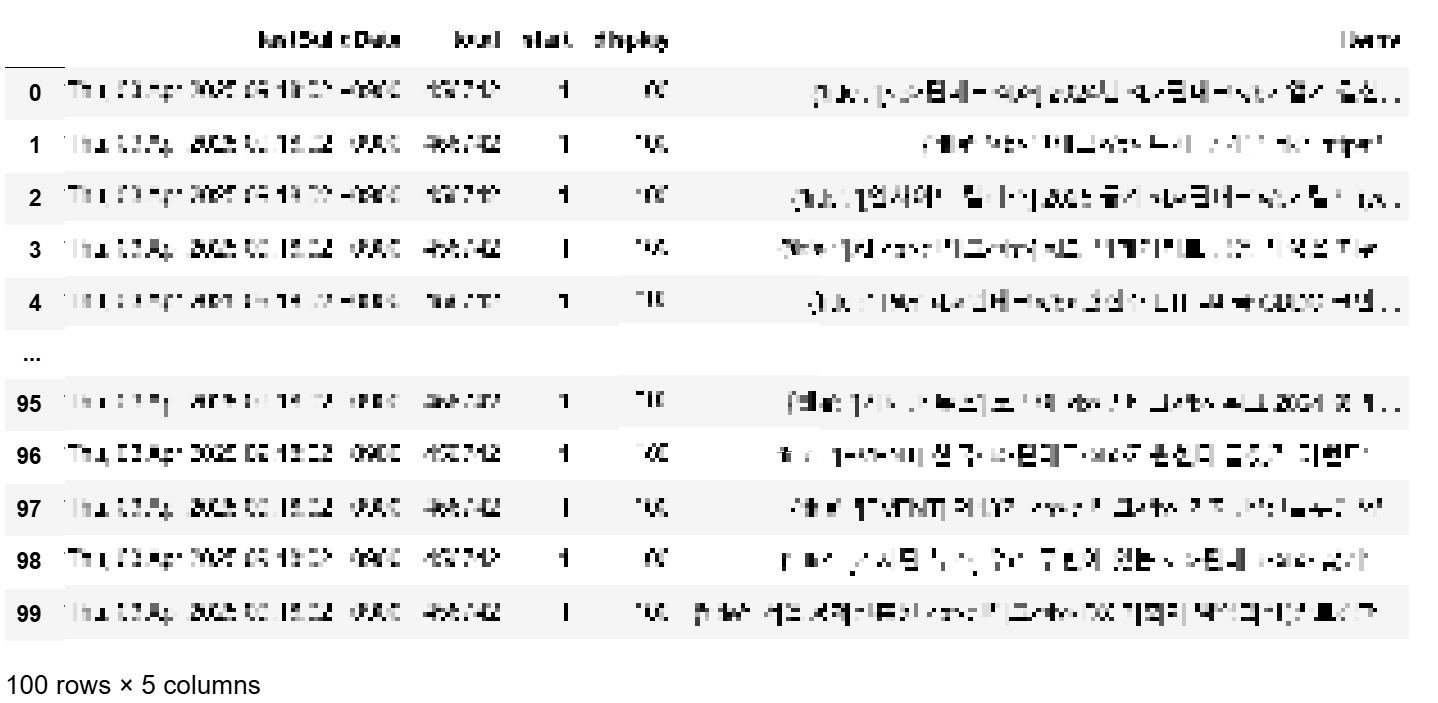
✔️ requests 모듈_네이버 API 활용
네이버 API 활용
네이버 검색 API 활용
책을 검색하고 결과를 데이터프레임으로 생성
검색어는 input()을 이용해 입력받은 값을 이용
검색 > 책 - Search API
검색 > 책 책 검색 개요 개요 검색 API와 책 검색 개요 검색 API는 네이버 검색 결과를 뉴스, 백과사전, 블로그, 쇼핑, 웹 문서, 전문정보, 지식iN, 책, 카페글 등 분야별로 볼 수 있는 API입니다. 그 외
developers.naver.com
import requests import pandas as pd # 원하는 단어를 입력하여 키워드에 할당(해당 키워드 값의 책 검색 결과 추출 위함) keyword = input('검색하고 싶은 키워드를 입력하세요: ') # 책 검색 데이터를 수집하기 위해 해당 url 할당 url = "https://openapi.naver.com/v1/search/book.json" # 위애서 네이버 책 검색 관련 페이지 확인하고 파라마터 적용 payload = dict(query = keyword, display = 100, start = 1, sort = 'sim') # 동일하게 자신의 Client_Id, Client_Secret 할당하여 사용 headers = {'X-Naver-Client-Id': Client_Id, 'X-Naver-Client-Secret': Client_Secret} # requests 모듈 get 방식으로 받아서 받아온 데이터 r에 할당 r = requests.get(url, params=payload, headers=headers)
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
# r에 할당된 전체 url 확인 print(r.url) # r에 할당된 상태 코드가 정상(200)인지 확인 print(r.status_code) # r에 할당된 파일의 문자열을 json에서 딕셔너리로 변환 data = r.json() print('전체 검색 데이터 수: ', data['total'])
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
# 추출된 키와 값을 result에 딕셔너리 형태로 할당 result={} # data의 items의 데이터가 필요한 데이터이므로 반복문을 통해 추출 for item in data['items']: for key, value in item.items(): result.setdefault(key, []).append(value) # result에 할당된 데이터를 데이터프레임으로 변환 및 확인 df = pd.DataFrame(result) df
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
네이버 API 활용(최대한 많은 데이터 추출)
네이버 API로 검색한 결과 최대한 가져오기
1. 1회 네이버 서버에 요청
2. 응답에서 total을 찾아서 display로 나누어 총 반복할 페이지 산출
3. 반복문 작성 및 종료 조건 설정
4. 반복이 끝난 후 리스트에 append된 데이터 프레임을 1개로 합침
5. 1페이지 결과를 데이터 프레임으로 만들고 리스트에 append
6. 반복이 끝난 후 리스트에 append된 데이터 프레임을 1개로 합침
네이버 API 활용 총 반복할 페이지 산출
# 원하는 단어를 입력하여 키워드에 할당(해당 키워드 값의 책 검색 결과 추출 위함) # 코드 실행마다 매번 키워드 입력을 피하기 위해 따로 작성하여 수행 keyword = str(input('검색하고 싶은 키워드를 입력하세요: '))
import requests # 책 검색 데이터를 수집하기 위해 해당 url 할당 # json 형식으로 데이터 수집 url = "https://openapi.naver.com/v1/search/book.json" # 동일하게 자신의 Client_Id, Client_Secret 할당하여 사용 headers = {'X-Naver-Client-Id': Client_Id, 'X-Naver-Client-Secret': Client_Secret} # 네이버 책 검색 관련 페이지 확인하고 파라마터 적용 payload = {'query': keyword, 'display': 100, 'start': 1, 'sort': 'sim'} # requests 모듈 get 방식으로 받아서 받아온 데이터 r에 할당 r = requests.get(url, params=payload, headers=headers) # r에 할당된 전체 url과 상태 코드 확인 # json 형식의 데이터를 딕셔너리로 변환하여 할당 print(r.url) print(r.status_code) data = r.json() # 전체 데이터의 수는 data의 total에 할당되어 있어 이를 숫자 형식 변환하여 할당 n_data = int(data['total']) # 검색할 페이지의 수 # +1 하는 이유 : 나머지가 존재할 시 1페이지 여유분 필요 # 전체 데이터의 수 // 파라미터의 display + 1 total_pages = ((n_data)//100)+1
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
# json 데이터를 데이터프레임으로 변환하는 함수 def json_unpack(data): result={} for item in data['items']: for key, value in item.items(): result.setdefault(key, []).append(value) df = pd.DataFrame(result) return df
print('전체 검색 데이터 수: ', n_data, '검색할 페이지 수: ', total_pages) result_df = json_unpack(data) result_df
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
전체 페이지의 데이터 스크래핑_for문 활용
for문 이용하여 전체 페이지 가져오기
1. 모든 검색 결과를 가져오기 위해서 여러 페이지 정보를 수집
2. 전체 결과 / 1페이지 표지 개수+1 = 전체 페이지수
3. start 부분 + 1페이지 개수 = 다음 페이지 데이터 수집 가능
4. 반복문을 이용해 start에서 100씩 더해서 최대 1000이 되도록 하면 최대한 많은 데이터 수집 가능
# 원하는 단어를 입력하여 키워드에 할당(해당 키워드 값의 책 검색 결과 추출 위함) keyword = input('검색하고 싶은 키워드를 입력하세요: ')
# 시작 페이지 설정 start_num = 1 result_json = [] # for문을 통해 전체 페이지를 범위로 반복하며 데이터 수집 진행 for page in range(total_pages): # 페이지 실행 과정 확인하기 위한 print문 print(f"{page+1}/{total_pages} 수집중", end='\r') # # 책 검색 데이터를 수집하기 위해 해당 url 할당 url = "https://openapi.naver.com/v1/search/book.json" # 네이버 책 검색 관련 페이지 확인하고 파라마터 적용 # 자신의 Client_Id, Client_Secret 할당하여 사용 payload = dict(query=keyword, display=100, start=start_num, sort="sim") headers = {'X-Naver-Client-Id': Client_Id, 'X-Naver-Client-Secret': Client_Secret} # requests 모듈 get 방식으로 받아서 받아온 데이터 r에 할당 r = requests.get(url, params=payload, headers=headers) # r에 할당된 전체 url과 상태 코드 확인 # json 형식의 데이터를 딕셔너리로 변환하여 할당 print(r.url) print(r.status_code) data = r.json() # 전체 데이터의 수와 전체 페이지의 수 확인 n_data = data['total'] total_pages = (n_data)//100)+1 # json 데이터를 데이터프레임으로 변환하는 함수 활용 # 해당 데이터를 result_json에 리스트 형식으로 저장 response = json_unpack(data) result_json.append(response) # if문을 활용하여 1000 달성하면 중지 # 901 전까지는 시작 페이지에 +100씩 설정 # 901인 경우는 시작 페이지에 +99 설정하여 반복 수행 if start_num == 1000: break elif start_num < 901: start_num += 100 elif start_num == 901: start_num += 99
# 리스트로 할당된 전체 데이터프레임 데이터를 concat 활용해 붙여서 데이터프레임으로 확인 final_result = pd.concat(result_json) # 합쳐진 데이터프레임의 index를 reset하여 처음이 0부터 시작하도록 변환 final_result = final_result.reset_index(drop=True) # 합쳐진 데이터프레임 확인 final_result
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
전체 페이지의 데이터 스크래핑_while문 활용
# 원하는 단어를 입력하여 키워드에 할당(해당 키워드 값의 책 검색 결과 추출 위함) keyword = input('검색하고 싶은 키워드를 입력하세요: ')
all_data2 = [] page = 1 start = 1 while True: # 책 검색 데이터를 수집하기 위해 해당 url 할당 url = "https://openapi.naver.com/v1/search/book.json" # 네이버 책 검색 관련 페이지 확인하고 파라마터 적용 # 자신의 Client_Id, Client_Secret 할당하여 사용 payload = {'query': keyword, 'display': 100, 'start': start, 'sort': 'sim'} headers = {'X-Naver-Client-Id': Client_Id, 'X-Naver-Client-Secret': Client_Secret} # requests 모듈 get 방식으로 받아서 받아온 데이터 r에 할당 r = requests.get(url, params=payload, headers=headers) # 요청 URL과 상태 코드 출력 # json 데이터를 딕셔너리로 변환 print(r.url) print(r.status_code) data = r.json() # 전체 데이터 수와 페이지 수 계산 n_data = data['total'] total_pages = (int(data['total'])//100)+1 # json 데이터를 데이터프레임으로 변환 (json_unpack 함수 사용) # 변환된 데이터를 all_data2 리스트에 추가 result_df = json_unpack(data) all_data2.append(result_df) # start가 1000되면 종료 # start가 901 미만이면 100씩 증가 # start가 901인 경우 99 증가 if start == 1000: break elif start < 901: start += 100 elif start == 901: start += 99 # 페이지 수가 전체 페이지 수보다 작으면 페이지 +1 # 페이지 수가 전체 페이지 수보다 크면 종료 if page < total_pages: page += 1 else: break
# 리스트로 할당된 전체 데이터프레임 데이터를 concat 활용해 붙여서 데이터프레임으로 확인 final_result2 = pd.concat(all_data2) # 합쳐진 데이터프레임의 index를 reset하여 처음이 0부터 시작하도록 변환 final_result2 = final_result2.reset_index(drop=True) # 합쳐진 데이터프레임 확인 final_result2
결과는 직접 해보시기 바랍니다. 결과는 코드에 따라 달라질 수 있습니다.
이번 내용에서는 requests 모듈을 사용한 네이버 API 활용 데이터 스크래핑에 대해 알아보았습니다.
파이썬(Python)을 활용한 데이터 스크래핑을 공부하고 정리해 나갈 예정이니,
파이썬으로 데이터 스크래핑을 공부하는데 도움이 되었으면 좋겠습니다.
데이터 스크래핑을 진행하며 for반복문과 while반복문, if문, 딕셔너리 구조가 중요하다는 것을 깨달았습니다.
파이썬의 반복문과 리스트, 딕셔너리 구조에 관한 블로그 글 참고하시면 좋을 것 같습니다.
[Python] 파이썬_파이썬 딕셔너리(dict)와 딕셔너리 함수 활용
데이터 분석을 위한 Python ✔️ 딕셔너리 활용✔️ 딕셔너리 함수✔️ 딕셔너리 함수 활용 ✔️ 딕셔너리 활용 딕셔너리 생성딕셔너리 사용dict 타입, JSON형이라고도 함web에서
everyonelove.tistory.com
[Python] 파이썬_파이썬 if else 조건문과 elif 다중 조건문, 조건표현식
데이터 분석을 위한 Python ✔️ if else 조건문✔️ elif 다중 조건문 ✔️ if else 조건문 if else 조건문 형식조건문특정 조건을 판별하여 작업을 분기 시키는 문법if else 조건문if 조건
everyonelove.tistory.com
[Python] 파이썬_파이썬 for 반복문과 enumerate(), continue, break
데이터 분석을 위한 Python ✔️ 반복문_for문✔️ 반복문 보조 함수와 제어 키워드 ✔️ 반복문_for문 for문for 반복문 : 반복할 횟수가 정해져 있는 경우순서가 있는 자료형(문자열,
everyonelove.tistory.com
[Python] 파이썬_파이썬 while문과 중첩반복문 활용
데이터 분석을 위한 Python ✔️ 반복문_while문✔️ 중첩반복문 ✔️ 반복문_while문 while문while : 반복할 횟수가 정해지지 않은 경우무한 반복 가능무한 반복이 되지 않도록 조건식을
everyonelove.tistory.com
데이터 분석과 관련된 다양한 정보들이 확인하고 싶다면
관심 있는 분들은 방문해서 좋은 정보 얻어가시길 바랍니다.
ECODATALIST
데이터 분석 공부 열심히 하는 중😁
everyonelove.tistory.com
'Python > 데이터 분석을 위한 데이터 스크래핑' 카테고리의 다른 글
| [Python] 데이터 스크래핑_ XML 데이터 스크래핑 및 공공데이터 API 활용 XML 데이터 스크래핑 (0) | 2025.04.07 |
|---|---|
| [Python] 데이터 스크래핑_ 공공데이터 API 신청 및 공공데이터 API 활용 데이터 스크래핑 (0) | 2025.04.06 |
| [Python] 데이터 스크래핑_네이버 API 신청 및 네이버 API 활용 데이터 스크래핑 (1) | 2025.04.02 |