
혼자 공부하는 SQL
✔️ 인덱스(INDEX)
✔️ 인덱스(INDEX)의 내부 작동
✔️ 인덱스 실제 사용
✔️ 인덱스(INDEX)
인덱스
DB 테이블의 특정 열(컬럼)에 대해 빠르게 검색하거나 정렬할 수 있도록 만드는 데이터 구조
클러스터형 인덱스 : 기본키를 지정(지정한 열을 기준 자동 정렬)하면 자동 생성되며 테이블에 1개만 생성 가능
보조 인덱스 : 고유 키로 지정하면 자동 생성되며 여러 개로 생성 가능
인덱스의 문제점
데이터를 빠르게 찾기 위한 인덱스의 생성이 너무 많아지면
필요 없는 인덱스가 나오게 되고 DB에서 차지하는 공간이 증가하면
인덱스를 이용해 데이터를 찾는 것이 전체 테이블을 찾는 것보다 느려질 수 있습니다.
MySQL은 인덱스를 사용할지 여부를 알아서 판단하고 활용합니다
인덱스의 장점
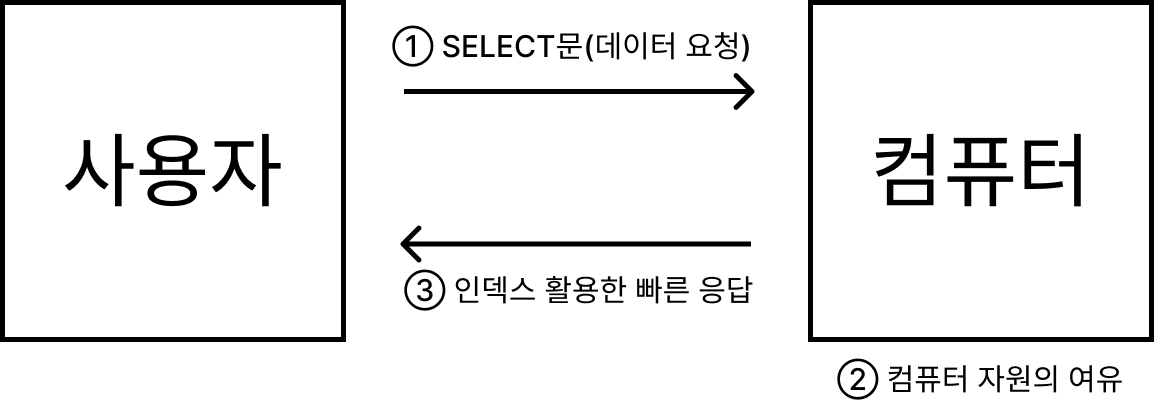
SELECT문의 효과를 빠르게 낼 수 있는 방법 중 하나
적절한 인덱스를 생성하고 활용한다면 기존보다 아주 빠른 응답속도를 가질 수 있습니다.
검색하는 속도의 상승은 전체 시스템의 성능 향상 효과 얻을 수 있습니다.
인덱스의 단점
인데스도 공간을 차지하기 때문에 DB의 추가적 공간 확보 필요하고
처음 인덱스를 생성하는데 오랜 시간이 걸릴 수 있습니다.
SELECT가 아닌 데이터의 변경 작업(INSERT, UPDATE, DELETE) 자주 일어나면 성능 나빠질 수 있습니다.
인덱스의 효과적 사용법
인덱스는 열 단위로 생성
where 절에서 사용되는 열에 인덱스 생성
where 절에 사용되더라도 자주 사용해야 가치 있음
데이터 중복이 높은 열은 인덱스를 만들어도 효과 미비
클러스터형 인덱스는 테이블당 하나만 생성 가능
사용하지 않는 인덱스는 제거
인덱스의 종류
자동으로 생성되는 인덱스
market_db의 회원(member) 테이블을 확인
CREATE TABLE member
( mem_id CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(기본키로 지정)
mem_name VARCHAR(10) NOT NULL,
mem_number INT NOT NULL,
addr CHAR(2) NOT NULL,
phone1 CHAR(3),
phone2 CHAR(8),
height SMALLINT,
debut_date DATE
);
인덱스(INDEX) 생성
만약 새로운 테이블을 생성하여 첫번째 열을 기본키로 지정한다면
-- 새로운 테이블 생성 및 기본키 지정
create table table1 (
col1 int primary key,
col2 int,
col3 int
);
-- 테이블의 인덱스 확인
show index from table1;
Non_Unique 값이 0으로 되어 있으니 중복을 허용하지 않는다는 의미
Key_name 부분을 보면 PRIMARY 되어 있는 부분이 기본 키로 설정하여 자동으로 생성된 인덱스라는 의미
Column_name이 col1 설정된 것은 col1 열에 인덱스가 만들어져 있다는 의미
2,3번째 열을 UNIQUE로 지정하여 생성
create table table1 (
col1 int primary key,
col2 int unique,
col3 int unique
);
-- 테이블의 인덱스 확인
show index from table1;
Key_name에 열이름이 적혀 있는 경우는 보조 인덱스라는 의미
동일하게 Non_Unique 값이 0으로 되어 있으니 중복을 허용하지 않는다는 의미
+
인덱스 제거
-- 인덱스 제거 기본 형식
ALTER TABLE 테이블명 DROP INDEX 인덱스명;
-- table1 테이블의 col1 열에 설정된 인덱스를 제거
alter table table1 drop index primary;
-- 기본 키(Primary Key) 인덱스를 제거하려면, 기본 키 제약 조건도 함께 제거
alter table table1 drop primary key;
클러스터형 인덱스
영어 사전과 같이 데이터가 이미 정렬되어 있는 인덱스의 활용
-- 새로운 member 테이블 생성
drop table if exists buy, member;
create table member (
mem_id char(8),
mem_name varchar(10),
mem_number int,
addr char(2)
);
insert into member values ('TWC', '트와이스', 9, '서울');
insert into member values ('BLK', '블랙핑크', 4, '경남');
insert into member values ('WMN', '여자친구', 6, '경기');
insert into member values ('OMY', '오마이걸', 7, '서울');
-- 생성된 테이블 확인
select
*
from member;
-- mem_id 열을 기본키로 설정
alter table member
add constraint
primary key(mem_id)
-- 변경된 테이블 확인
select * from member;
mem_id의 Primary Key 제거하고 mem_name열을 Primary key로 지정한다면
-- 기본키 지정 제거
alter table member drop primary key;
alter table member
add constraint
primary key(mem_name)
-- 변경된 테이블 확인
select * from member;
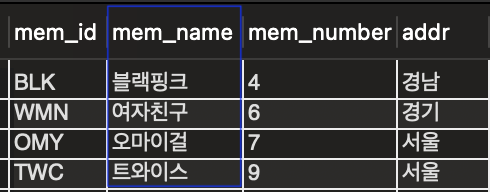
추가로 입력되는 데이터는 기본키를 기준으로 정렬되는 것을 확인 가능
보조 인덱스
일반적인 책과 같이 뒷부분에 찾아볼 수 있는 보기 제공과 같은 인덱스의 활용
테이블은 이미 완성되어 있고 그 중에서 보조 인덱스를 활용해 데이터를 찾는 기능 수행
-- 새로운 member 테이블 생성
drop table if exists buy, member;
create table member (
mem_id char(8),
mem_name varchar(10),
mem_number int,
addr char(2)
);
insert into member values ('TWC', '트와이스', 9, '서울');
insert into member values ('BLK', '블랙핑크', 4, '경남');
insert into member values ('WMN', '여자친구', 6, '경기');
insert into member values ('OMY', '오마이걸', 7, '서울');
-- 생성된 테이블 확인
select
*
from member;
-- mem_id를 UNIQUE로 지정
alter table member
add constraint
unique(mem_id)
-- 변경된 테이블 확인
select * from member;
mem_id의 Unique 제거하고 mem_name열을 Unique로 지정한다면
-- Unique 지정
alter table member
add constraint
unique(mem_name);
-- 변경된 테이블 확인
select * from member;
추가로 입력되는 데이터는 테이블의 맨 밑에 추가되는 것을 확인 가능
✔️ 인덱스(INDEX)의 내부 작동
균형 트리
나무를 거꾸로 표현한 자료 구조
클러스터형 인덱스와 보조 인덱스는 모두 내부적으로 균형 트리로 만들어집니다.
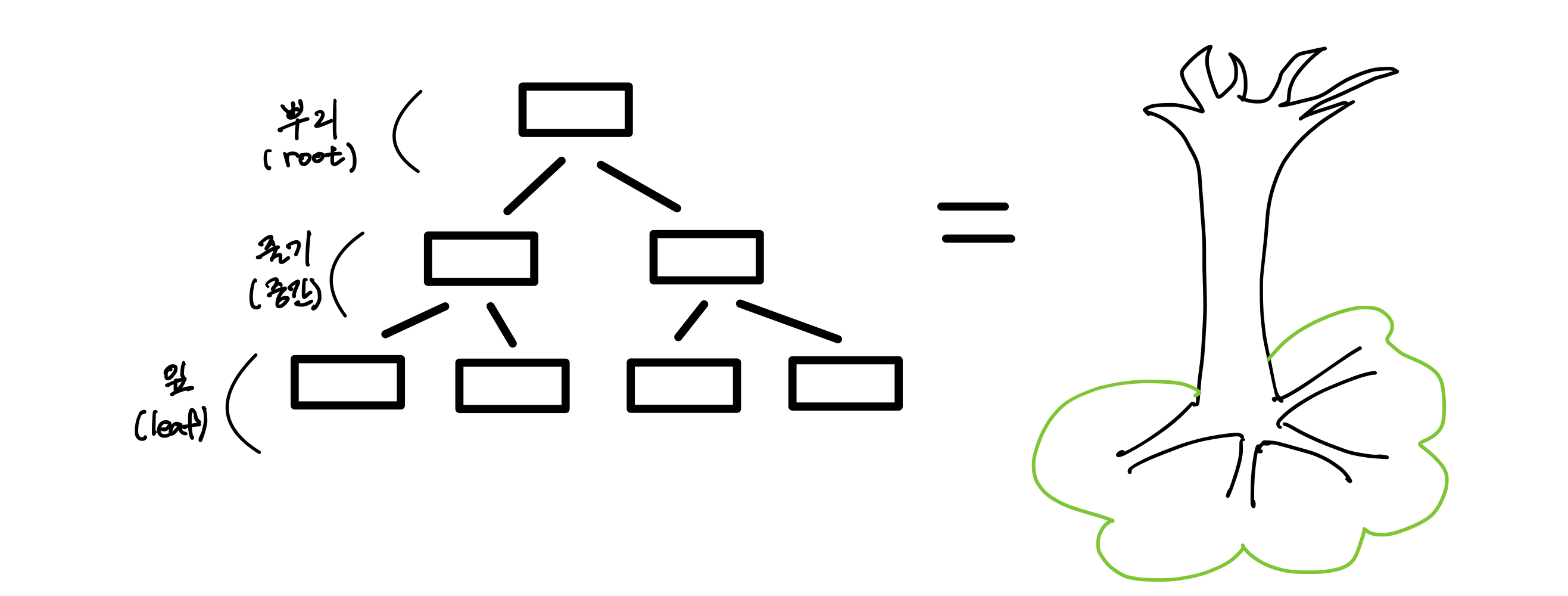
균형 트리 구조
균형 트리에서 데이터가 저장되는 공간 : 노드(Node)
= MySQL의 페이지(page)
루트 노드(root node) : 노드의 가장 상위 노드
리프 노드(leaf node) : 노드의 제일 마지막에 존재하는 노드
중간 노드(internal node) : 루프 노드와 리프 노드 중간의 노드
균형 트리는 SELECT문을 사용한 데이터 검색 시 뛰어난 성능 발휘합니다.
균형 페이지는 2페이지만 확인하면 데이터 검색 가능(균형 페이지 아닌 경우는 3페이지 확인)
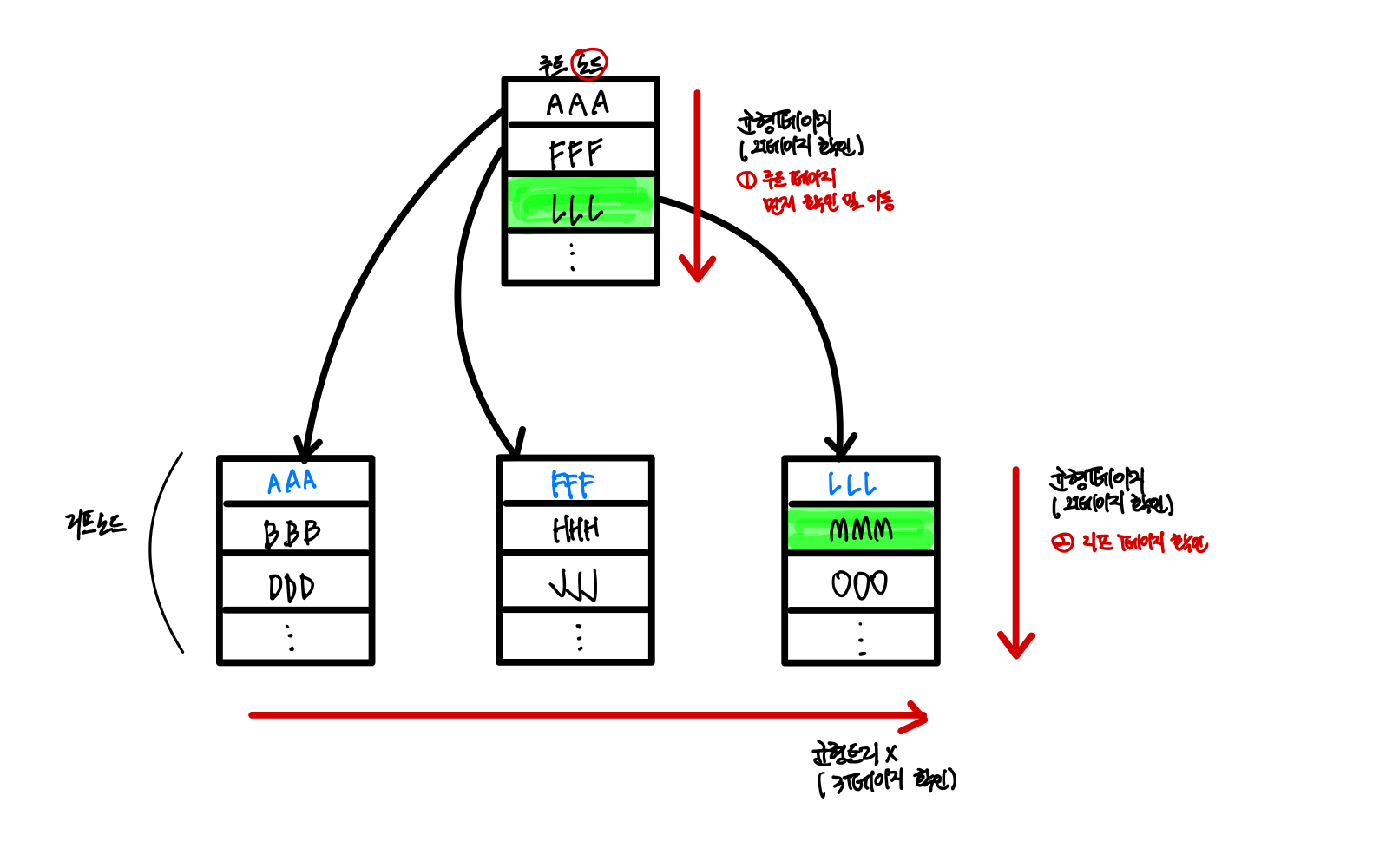
균형 트리의 페이지 분할
인덱스 구성 시, 데이터 변경 작업(INSERT, UPDATE, DELETE) 시 성능이 나빠집니다.
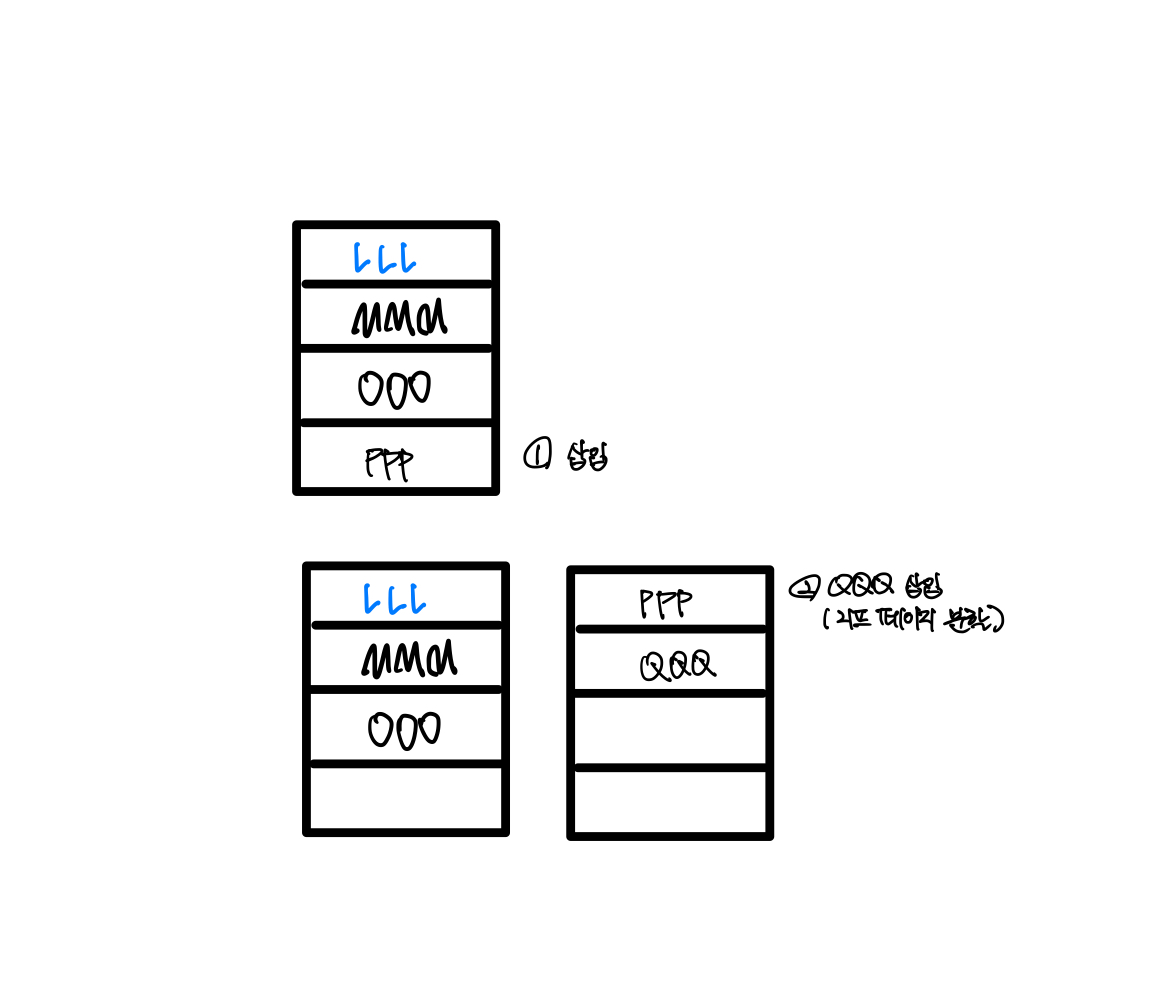
페이지 분할
새로운 페이지를 준비하여 데이터를 나누는 작업
① 2번째 리프 페이지에 빈 공간이 있어 JJJ를 한 칸 이동
② 그 자리에 III 입력됨
③ 새로운 페이지를 루트에 등록
④ 페이지 분할(새로운 페이지)


PPP와 QQQ 2개를 연속해서 입력하는 경우
① 4번째 리프 페이지에 PPP 삽입
② QQQ 삽입( 자리가 없으므로 페이지 분할 수행)
③ 루트 페이지의 페이지 분할 수행
④ 루트 페이지의 페이지 분할로 인한 중간 페이지 형성
인덱스 구조
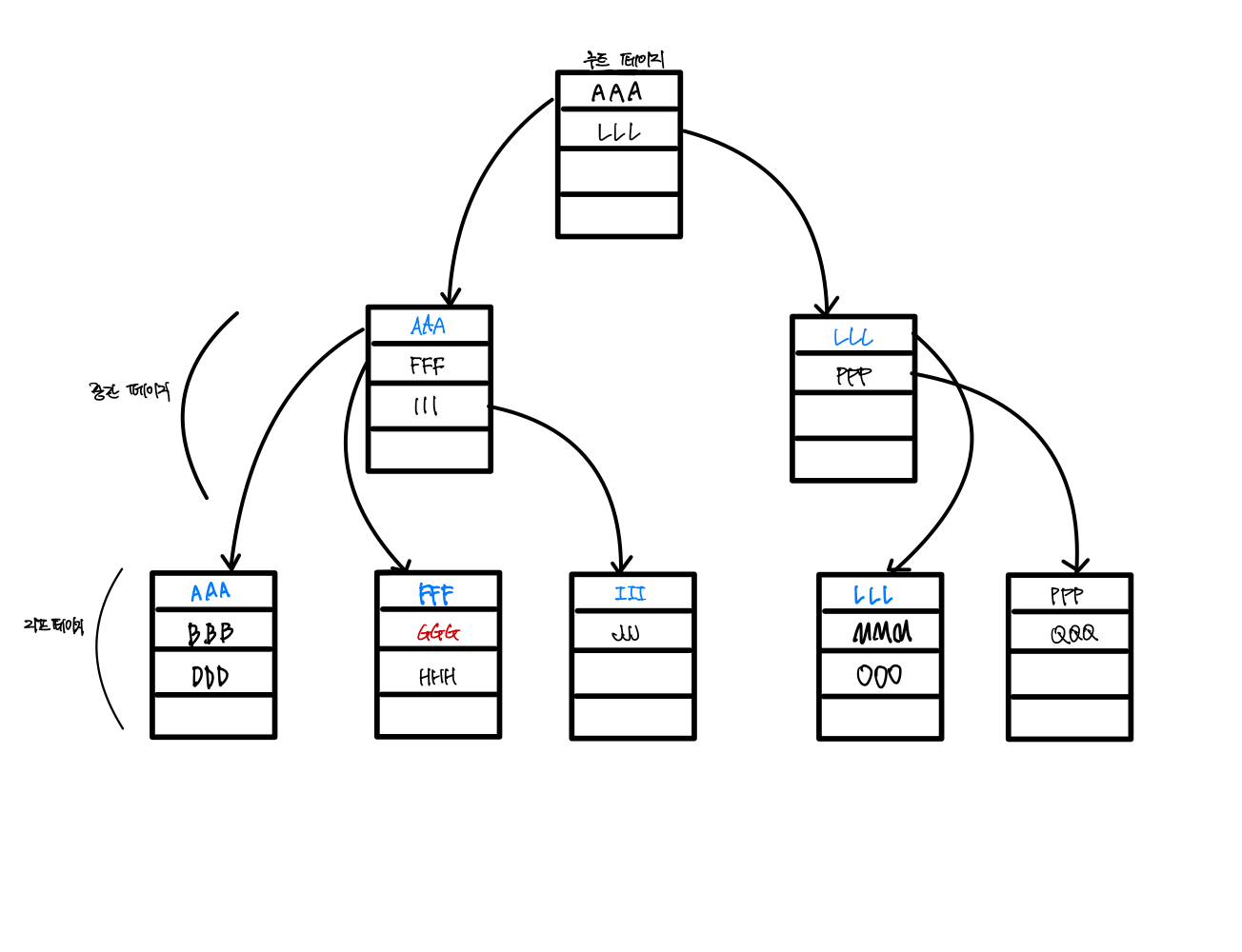
클러스터형 인덱스 구성
클러스터형 인덱스 구조 파악 및 인덱스 페이지 확인
-- cluster 테이블 생성
drop table if exists cluster;
create table cluster (
mem_id char(8),
mem_name varchar(10)
);
-- 데이터 입력은 결과표 보고 진행하기
-- 입력된 데이터 확인
select
*
from cluster;
-- 클러스터형 인데스 구성
alter table cluster
add constraint
primary key(mem_id);
-- 변경된 데이터 확인
select
*
from cluster;
+
클러스터형 인덱스인 경우 인덱스 페이지 구성
인덱스 페이지 = 루트 페이지 + 리프 페이지(데이터 페이지)
보조 인덱스 구성
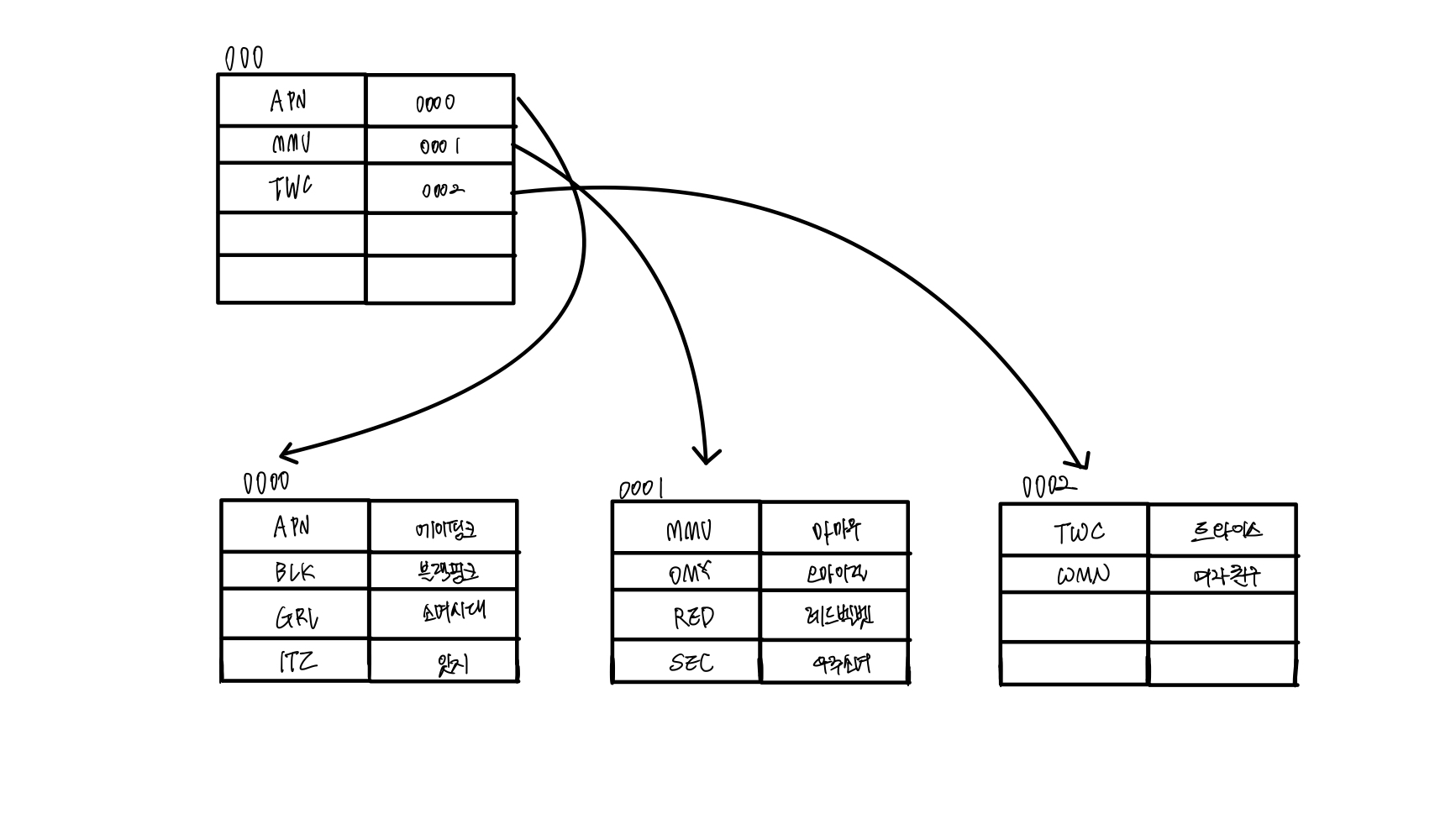
보조 인덱스 구조 파악 및 인덱스 페이지 확인
-- second 테이블 생성
drop table if exists second;
create table second (
mem_id char(8),
mem_name varchar(10)
);
-- 데이터 입력은 결과표 보고 진행하기
-- 입력된 데이터 확인
select
*
from cluster;
-- 보조 인데스 구성
alter table second
add constraint
unique (mem_id);
-- 변경된 데이터 확인
select
*
from second;
+
보조 인덱스인 경우 인덱스 페이지 구성
인덱스 페이지 = 루트 페이지 + 리프 페이지
데이터 페이지는 따로 나누어져 리프 페이지에서 페이지 번호+#위치를 찾아 데이터 확인 가능

인덱스 검색을 통해 확인하면 클러스터형 인덱스가 보조 인덱스보다 약간 더 빠르다는 것 확인 가능
✔️ 인덱스 실제 사용
SQL을 활용한 인덱스 생성의 기본 형식
직접 인덱스를 생성하기 위해 CREATE INDEX문(보조 인덱스)사용
UNIQUE : 중복이 안 되는 고유의 인덱스 생성
ASC / DESC : 인덱스의 오름차순, 내림차순 정렬 수행
-- 인덱스 생성
create [UNIQUE] index 인덱스명
on 테이블명(열_이름) [ASC | DESC];
SQL을 활용한 인덱스 제거의 기본 형식
인덱스를 제거하기 위해 DROP INDEX문 사용
기본키, 고유 키로 자동 생성된 인덱스(클러스터형 인덱스)는 제거되지 않음
-- 인덱스 제거
drop index 인덱스명 on 테이블명;
market_db를 활용한 인덱스 생성과 제거
클러스터형 인덱스 생성하고 member 테이블의 인덱스 확인
use market_db;
-- member 테이블 확인
select * from member;
-- member 테이블에 생성된 인덱스 정보 확인
show index from member;
-- 1페이지에 16KB 할당됨
-- index_length(보조 인덱스의 크기)
show table status like 'member';

주소(addr)의 중복을 허용하는 단순 보조 인덱스 생성
-- 단순 보조 인덱스 생성
-- idx = index의 약자
-- 인덱스명은 바로 확인할 수 있는 것으로
create index idx_member_addr
on member(addr);
-- 생성된 인덱스 확인
show index from member;
(Non_unique가 1로 설정되어 있다면 고유 보조 인덱스는 아니라는 의미 = 중복된 데이터를 허용)
+
보조 인덱스를 추가한 후 전체 인덱스의 크기 확인
show table status like 'member';
기존과 동일한 index_length는 0이 나옴
보조 인덱스 idx_member_addr을 생성되었다면,
생성한 인덱스가 적용되지 않았다는 의미입니다.
ANALYZE TABLE
생성한 인덱스를 실제로 적용시키기 위해 테이블을 분석 및 처리 수행
-- 생성한 인덱스의 적용
analyze table member;
인덱스 적용 후 보조 인덱스의 크기 확인
-- 인덱스의 적용 및 보조 인덱스의 크기 확인
show table status like 'member';
+
중복을 허용하지 않는 경우
-- 중복을 허용하징 않는 고유 보조 인덱스 생성
create unique inde idx_member_mem_number
on member(mem_name);
-- 인덱스의 적용 및 보조 인덱스의 크기 확인
analyze table member;
show index from member;
인덱스 사용했는지 여부 확인
Execution Plan창 확인
(Full Table Scan을 제외한 나머지는 모두 인덱스를 사용했다는 의미)
-- 인덱스가 생성된 테이블의 행 조회
-- 인덱스를 사용한 것을 확인
select
mem_id,
mem_name,
addr
from member
where mem_name = '에이핑크';
-- 숫자의 범위로 조회
create index idx_member_number
on member (mem_number);
analyze table member;
select
mem_name,
mem_number
from member
where mem_number >= 7;
인덱스를 사용하지 않은 경우
where절에 연산을 사용하는 경우는 인덱스를 사용하지 않습니다.
(where절에는 왠만하면 연산을 사용하지 않는 것을 추천)
-- 인덱스 사용 여부 확인
select
mem_name,
mem_number
from member
where mem_number >= 1;
-- 위와 동일한 경우
select
mem_name,
mem_number
from member
where mem_number*2 >= 14;
-- where mem_number >= 14/2 와도 동일
인덱스 제거
보조 인덱스 제거
-- 인덱스의 이름 확인
show index from member;
-- 보조 인덱스 제거
drop index idx_member_mem_number on member;
drop index idx_member_addr on member;
drop index idx_member_number on member;
-- 클러스터형 인덱스 제거
alter table member
drop primary key;
-- member의 mem_id 열을 buy가 참조하기 때문에 수행되지 않음
클러스터형 인덱스 제거
-- 외래 키의 이름 확인
-- infromation_schema DB의 referential_constraints 테이블 조회 통해 외래키 확인 가능
select
table_name,
constraint_name
from information_schema.referential_constraints
where constraint_schema = 'market_db';
-- 확인한 외래키를 먼저 제거 후 기본 키 제거 수행
alter table buy
drop foreign key buy_ibfk_1;
alter table member
drop primary key;
-- 인덱스 확인
show index from member;

(외래키 확인 후 클러스터형 인덱스를 제거하기 위해 PRIMARY KEY까지 제거하니 인덱스가 없는 것을 확인)
이상으로 5주차 내용 정리를 마무리 하겠습니다.
혹시나 공부를 원하시는 분은 해당 도서를 구매하셔서 공부하는 더 좋을 것 같습니다.
혼자 공부하는 SQL
아무런 사전 지식 없는 입문자가 ‘꼭 필요한 내용을 제대로’ 학습할 수 있도록 구성했다. ‘무엇을’, ‘어떻게’ 학습해야 할지조차 모르는 입문자의 막연한 마음을 살펴, 과외 선생님이 알
www.aladin.co.kr
15강부터 17강까지의 내용을 다루고 있으니 궁금하신 분은 유튜브를 참고하여 공부하면 좋을 것 같습니다.
'SQL > 혼자 공부하는 SQL' 카테고리의 다른 글
| [혼공S] 6주차_파이썬과 MySQL 연동 및 GUI 프로그램 활용 (0) | 2025.02.17 |
|---|---|
| [혼공S] 6주차_스토어드 프로시저, 스토어드 함수(커서)와 트리거 (0) | 2025.02.16 |
| [혼공S] 4주차_제약조건을 활용한 테이블 및 가상 테이블(VIEW) 생성 및 활용 (0) | 2025.02.03 |
| [혼공S] 3주차_MySQL 데이터 형식과 JOIN(조인), SQL 프로그래밍 활용 (1) | 2025.01.23 |
| [혼공S] 2주차_SELECT문과 WHERE절 활용 (0) | 2025.01.18 |